É possível monitorar os erros de leitura do HD (mesmo antes dos badblocks começarem a aparecer) usando o SMART, um recurso de monitoramento disponível em todos os HDs modernos, onde a própria controladora monitora o status do HD e disponibiliza um log numa área reservada, que pode ser lida pelo sistema operacional.
No Linux, este recurso é disponibilizado através do “smartmontools“, um pacote disponível nos repositórios da maioria das distribuições e também no http://smartmontools.sourceforge.net/.
O smartmontools é baseado no “smartsuite”, um pacote mais antigo, que ainda é incluído em algumas distribuições (como no Debian), mas que oferece menos funções e não é mais desenvolvido ativamente.
A maior parte das funções podem ser acessadas usando o utilitário “smartctl“, incluído no pacote. Comece usando a opção “-i”, seguida do device do HD (como em “smartctl -i /dev/hda”) para ver informações sobre o drive:

Note que neste caso, embora o SMART seja suportado pelo drive, ele está desativado. Antes de mais nada, precisamos ativá-lo, usando o comando:
# smartctl -s on /dev/hda
Para um diagnóstico rápido da saúde do drive (fornecido pela própria controladora), use o parâmetro “-t short“, que executa um teste rápido, de cerca de dois minutos, e (depois de alguns minutos) o parâmetro “-l selftest” que exibe o relatório do teste:
# smartctl -t short /dev/hda
Sending command: “Execute SMART Short self-test routine immediately in off-line mode”.
Drive command “Execute SMART Short self-test routine immediately in off-line mode” successful. Testing has begun.
Please wait 2 minutes for test to complete.
# smartctl -l selftest /dev/hda
Este comando exibe um relatório de todos os autotestes realizados e o status de cada um. Num HD saudável, todos reportarão “Completed without error”.
Você pode executar também um teste longo (que dura cerca de uma hora) usando o parâmetro “-t long“. Ambos os testes não interferem com a operação normal do HD, por isso podem ser executados com o sistema rodando. Em casos de erros, o campo “LBA_of_first_error” indica o número do primeiro setor do HD que apresentou erros de leitura, como em:
Status Remaining LBA_of_first_error
Completed: unknown failure 90% 0xfff00000
Nestes casos, execute novamente o teste e verifique se o erro continua aparecendo. Se ele desaparecer no teste seguinte, significa que o setor defeituoso foi remapeado pela controladora, um sintoma benigno. Caso o erro persista, significa que não se trata de um badblock isolado, mas sim o indício de um problema mais grave.
O parâmetro “-H” (health) exibe um diagnóstico rápido da saúde do drive, fornecido pela própria controladora:
# smartctl -H /dev/hda
SMART overall-health self-assessment test result: PASSED
Neste caso, o SMART informa que não foi detectado nenhum problema com o drive. Em casos de problemas iminentes, ele exibirá a mensagem “FAILING“. Este diagnóstico da controladora é baseado em várias informações, como erros de leitura, velocidade de rotação do disco e movimentação da cabeça de leitura.
Um disco “FAILING” não é um local seguro para guardar seus dados, mas em muitos casos ainda pode funcionar por alguns meses. Se ainda não houver muitos sintomas aparentes, você pode aproveitá-los em micros sem muita importância, como estações que são usados apenas para acessar a Web, que não armazenam dados importantes. Note que, embora relativamente raro, em muitos casos o drive pode realmente se perder menos de 24 horas depois de indicado o erro, por isso transfira todos os dados importantes imediatamente.
Você pode ver mais detalhes sobre o status de erro do HD usando o parâmetro “-A“, que mostra todos os atributos suportados pelo HD e o status de cada um. Na sexta coluna (Type) você pode verificar a importância de cada um; os marcados como “Old_age” indicam sintomas de que o HD está no final de sua vida útil, mas não significam por si só problemas iminentes. Os mais graves são os “Pre-Fail”, que indicam que o HD está com os dias contados.
Na coluna “WHEN_FAILED” (a mais importante), você vê o status de cada opção. Num HD saudável, esta coluna fica limpa para todas as opções, indicando que o HD nunca apresentou os erros:
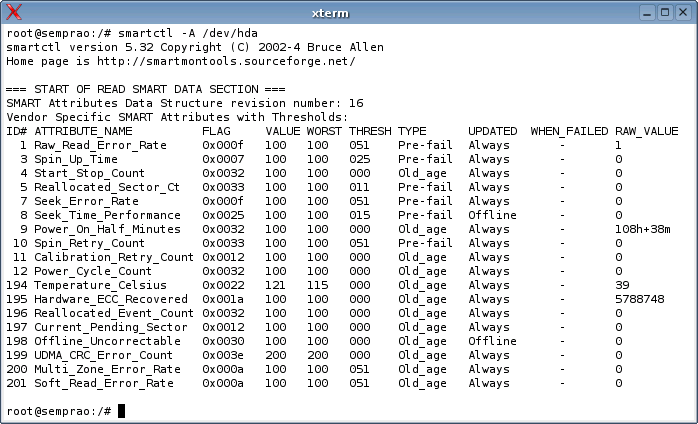
O número de setores defeituosos no drive (não remapeados) pode ser visto nos atributos “197 Current_Pending_Sector” e “198 Offline_Uncorrectable”, onde o número de badblocks é informado na última coluna. Em situações normais, os badblocks não remapeados contém pedaços de arquivos, que a controladora muitas vezes tenta ler por muito tempo antes de desistir.
Em casos extremos, onde existam vários badblocks não marcados, você pode usar o truque de encher o HD com zeros, usando o comando “dd if=/dev/zero of=/dev/hda” para forçar a controladora a escrever em todos os blocos e assim remapear os setores (perdendo todos os dados, naturalmente).
O número de setores defeituosos já remapeados, por sua vez, pode ser acompanhado através dos atributos “5 Reallocated_Sector_Ct” e “196 Reallocated_Event_Count”.
Naturalmente, não basta executar estes testes apenas uma vez, pois erros graves podem aparecer a qualquer momento. Você só terá segurança se eles forem executados periodicamente.
Para automatizar isso, existe o serviço “smartd” (“smartmontools” no Debian), que fica responsável por executar o teste a cada 30 minutos e salvar os resultados no log do sistema, que você pode acompanhar usando o comando “dmesg“.
No caso do Debian, além de configurar o sistema para inicializar o serviço no boot, você precisa configurar também o arquivo “/etc/default/smartmontools“, descomentando a linha “start_smartd=yes“.
O padrão do serviço é monitorar todos os HDs disponíveis. Você pode também especificar manualmente os HDs que serão monitorados e os parâmetros para cada um através do arquivo “/etc/smartd.conf“.
Comece comentando a linha “DEVICESCAN”. O arquivo contém vários exemplos de configuração manual. Uma configuração comum é a seguinte:
/dev/hda -H -l error -l selftest -t -I 194 -m tux@gmail.com
Esta linha monitora os logs do “/dev/hda” (erros e testes realizados) e monitora mudanças em todos os atributos (incluindo a contagem de badblocks e setores remapeados), com exceção da temperatura (que muda freqüentemente), e envia e-mails para a conta especificada sempre que detectar mudanças. Para que ele use apenas o log do sistema, sem enviar o e-mail, remova a opção “-m”.
Para que os relatórios via e-mail funcionem, é preciso que exista algum MTA instalado na máquina, como o Sendmail ou o Postfix. O smartd simplesmente usa o comando “mail” (que permite o envio de e-mails via linha de comando) para enviar as mensagens. No Debian (além do MTA) é necessário que o pacote “mailutils” esteja instalado.
Depois de alterar a configuração, lembre-se de reiniciar o serviço, usando o comando:
# /etc/init.d/smartd restart
ou:
# /etc/init.d/smartmontools restart
Caso o SMART indique algum erro grave e o HD ainda esteja na garantia, você pode imprimir o relatório e pedir a troca.
A vida útil média de um HD IDE é de cerca de dois anos de uso contínuo. HDs em micros que não ficam ligados continuamente podem durar muito mais, por isso é saudável trocar os HDs dos micros que guardam dados importantes anualmente e ir movendo os HDs mais antigos para outros micros.
Normalmente, os fabricantes dão um ano de garantia para os HDs destinados à venda direta ao consumidor e seis meses para os HDs OEM (que são vendidos aos integradores, para uso em micros montados, mas que freqüentemente acabam sendo revendidos). Uma dica geral na hora de comprar HDs é nunca comprar HDs com apenas três meses de garantia, que normalmente é dada só para HDs remanufaturados.



Deixe seu comentário