
Os primeiros buscadores
Como você deve saber, a Internet surgiu em meados da década de 1970. Naquela época, ela estava restrita apenas a instituições militares e acadêmicas. Seus usuários usavam serviços como Telnet, FTP e e-mail. Na década de 1980, popularizaram-se os BBS, sistemas computacionais que permitiam a seus usuários ler notícias, trocar mensagens e fazer download e upload de arquivos.
Foi apenas no começo da década de 1990 que Tim Berners-Lee criou a World Wide Web, a qual permitiria a troca de informações através do protocolo de transferência de hipertextos, o HTTP. É importante saber, portanto, que a Internet é muito maior do que a web, mas que a web é a parte da internet mais acessada no mundo.
Com o advento da internet comercial, começaram a surgir vários websites, páginas criadas por empresas e usuários comuns na grande teia mundial. Posto que o número de sites já ultrapassava as dezenas de milhares, era necessário ter algum tipo de “lista telefônica” que permitisse aos usuários encontrar rapidamente as informações que procuravam. Surgiram, aí, os sites de busca que, no começo, eram basicamente de três tipos: os diretórios, os “crawlers” e os metabuscadores.
Os diretórios são sites especializados em coletar, armazenar e categorizar links para outros sites. Eles funcionam com base em três elementos: título, palavras-chave e descrição. Todas essas informações podem ser encontradas na seção <head> de uma página web. Nesses sites, você digita as palavras chaves que deseja pesquisar e ele retorna o título da página, com sua descrição e endereço. O Yahoo!, um dos primeiros sites de busca que surgiu na Internet, era, originalmente, um diretório, assim como o brasileiro Cadê?, hoje comprado pelo Yahoo!. Atualmente, o DMOZ (Link: http://www.dmoz.org/ ) é um dos poucos diretórios que ainda restam, editado por humanos.

Página inicial do Yahoo! Em meados de 1997.
Os crawlers funcionavam de maneira semelhante ao Google. Ao invés de armazenar apenas o título, as palavras-chave e a descrição, eles guardavam, também, o conteúdo das páginas, tornando a busca mais precisa. O Altavista, hoje parte do Yahoo!, era um dos principais crawlers e maiores sites de busca do final da década de 90.
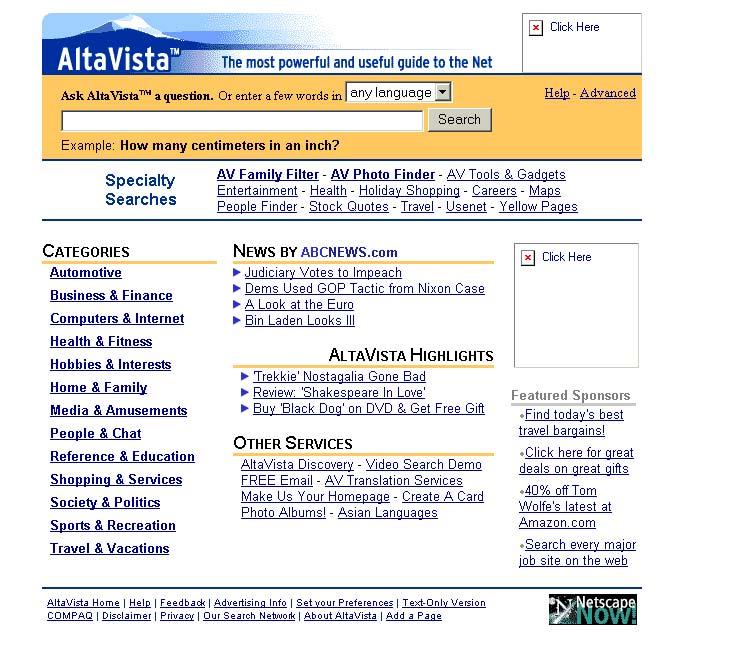
Página inicial do Altavista em Dezembro de 1998
Já os metabuscadores, como o HotBot, diferenciavam-se dos dois primeiros por serem “sanguessugas”, no melhor sentido da palavra. Ao contrário dos diretórios e dos crawlers, eles não tinham um banco de dados próprio, mas retornavam ao usuário resultados de outros sites de busca.
Assim, vemos que, antes do Google, o mercado de sites de busca na web era dominado por basicamente três tipos de sites: os diretórios, os crawlers e os metabuscadores. Todos eles, no entanto, tinham falhas graves.
Se tanto os diretórios quanto os crawlers armazenavam links de outras páginas, a questão fundamental é: quem vai aparecer em primeiro lugar quando o usuário fizer uma busca? A classificação deveria ser justa para todos, logo, não poderia ser feita por ordem alfabética ou pelo último site cadastrado. Assim, a maioria dos sites de busca se guiava pelas palavras-chave contidas na página para ordenar seus resultados – e é aí que a questão ficava complicada.
Digamos que você estivesse procurando por uma empresa de aluguel de carros em Porto Alegre. Assim, você digitaria algo como “aluguel carros porto alegre” na caixa de pesquisa e o buscador retornaria todas as páginas que tivessem aquelas palavras. O problema é que esse sistema é muito simples de ser enganado tanto nos diretórios quanto nos crawlers.
Nos diretórios, o que é pesquisado são apenas as palavras-chave e a descrição do site, não o conteúdo em si. Logo, era frequente fazer um “spam” de palavras-chave para conseguir mais cliques. Logo, era grande a chance de você pesquisar sobre um site de aluguel de carros e cair em uma página sem relação ao conteúdo ou, no pior dos casos, com conteúdo adulto ou malicioso.
Embora os crawlers tenham solucionado em parte o problema dos diretórios ao pesquisar no conteúdo em si da página e não apenas em suas palavras-chave, também era relativamente simples enganá-los. Muitos webmasters colocavam determinadas palavras-chave em excesso ou em textos ocultos, isto é, da mesma cor do fundo da página, fazendo com que seus sites avançassem em posição, fazendo o usuário correr o risco de encontrar apenas lixo em suas pesquisas.
Portanto, com os dois métodos principais ineficientes, era necessário uma nova forma de ordenar os resultados de pesquisa.
Surge o Google
Em 1998, os estudantes de doutorado Sergey Brim e Larry Page lançaram o projeto no qual eles já estavam trabalhando há dois anos: o BackRub que, mais tarde, viria a ser chamado de Google, uma referência ao gugol, que corresponde ao número 1 seguido de 100 zeros.
O descompromissado projeto de faculdade viria a ter um crescimento exponencial logo em seus primeiros anos, deixando para trás todos os líderes do mercado de busca existentes até então. Tal façanha se deve principalmente a dois fatores: seu design simples e o poderoso algoritmo Page Rank.

Página inicial do Google em 1999.
Conforme você pode verificar ao analisar as imagens desse texto, as páginas iniciais dos sites de buscas na década de 90 eram lotadas de links que levavam ou para categorias de sites, ou para serviços do usuário, como e-mail e chat, ou mesmo para anúncios publicitários. O Google, porém, resolveu apostar na simplicidade, que se tornaria sua marca registrada, colocando em frente ao usuário apenas sua principal ferramenta: o formulário de pesquisa. O visual clean caiu no gosto popular, chegando a ser copiado pelos concorrentes, e foi um dos principais fatores para a popularização do site.
Enquanto a maioria dos buscadores ordenava os resultados das pesquisas por base nas palavras-chave de cada página, o que podia dar margem para fraudes, o pessoal do Google resolveu seguir por outro caminho, ordenando as páginas por sua importância. Para tal, eles desenvolveram uma série de algoritmos chamados de PageRank, que atribui um valor de 1 a 10 para cada site; quanto maior o valor, mais importante é o site. Um link do site A para o site B representa um voto do site A para o B. Quanto maior o PageRank de uma página, mais peso tem o voto e, assim, com base nos links que uma página recebe, determina-se a ordem dos resultados da pesquisa.
Logo, o Google revolucionou a Web não apenas por seu design simples, mas principalmente pela sua maneira inovadora de classificar as páginas, o que, silenciosamente, ditou as novas regras de se construir páginas. Se, antes, devido à própria natureza dos buscadores, não havia uma grande preocupação sobre o layout e a organização interna das páginas, a necessidade de se aparecer nas primeiras posições do Google abriu um novo mercado: o SEO, que foi responsável por fazer da internet um lugar melhor.
Privacidade: o calcanhar de Aquiles do gigante de Mountain View
Mas nem tudo são flores na trajetória de sucesso do gigante das buscas. Desde seus primeiros dias, a empresa enfrentava problemas em relação aos tratamentos dispensados aos dados de seus usuários – e a lista aumenta a cada dia.
Logo que começou a se tornar conhecido no Brasil e no mundo, no início dos anos 2000, surgiu uma grande polêmica em relação ao chamado “cookie imortal” do Google. Cookies são pedaços de informação que os sites gravam em seu disco rígido para se lembrar de suas preferências. Eles permitem, por exemplo, que você faça login em uma página, feche o navegador e, quando abri-lo de novo, a página estará mostrando seu perfil, sem a necessidade de se autenticar novamente. O problema é que o cookie do Google estava originalmente programado para expirar em 2038, 40 anos após a fundação da empresa! Somado ao fato de que o cookie atribui uma identificação única para cada computador e que a empresa registra todas as buscas que você faz, isso poderia significar que eles poderiam manter um registro de toda sua vida com base nas suas buscas (atualmente, o cookie do Google está programado para expirar em 2014, veja em seu navegador).
Com o crescimento da empresa, a preocupação com a privacidade aumentou: eles compraram o primeiro serviço de blogs mundial, o Blogger, criaram um serviço de e-mail próprio, o gMail, um de seus funcionários, chamado Orkut Buykkokten, criou um site de relacionamentos que foi muito famoso no Brasil e, posteriormente, a empresa lançou o Google+, para concorrer com o Facebook e tem botões +1 – que registram os seus rastros, independente de você estar ou não na rede – espalhados por praticamente todos os sites; O serviço de e-mail exibe publicidades com base no conteúdo das mensagens que você recebeu – embora eles garantam que não leiam a sua correspondência; o Google Buzz foi um fiasco completo e teve de ser desativado para evitar maiores complicações; uma interpretação dos termos de serviço do Google Drive dá a entender que todos os arquivos pessoais que você envia passam a ser de propriedade da empresa; e, por último, os novos termos de uso unificados, que entraram em vigor há alguns meses, já fizeram muitos desistirem de usar os serviços da empresa que diz não ser má – sem falar que eles estão por trás do sistema operacional da maioria dos smartphones do mundo!
Largar o Google pode não ser fácil, embora haja alternativas com recursos interessantes que não existem no buscador da Califórnia, como o DuckDuckGo (link: www.duckduckgo.com ) , que promete respeitar a privacidade do usuário e tem ferramentas adicionais de busca. É indubitável que o Google conseguiu se impor e mudar a web para melhor. Mas a pergunta que não quer calar é: estamos prontos para viver sem ele?



Deixe seu comentário