Dentro do processador, as mudanças começam com a inclusão do Decoped Uop Cache, um cache “L0” que armazena 1.500 instruções decodificadas (equivalente a 6 KB de dados). Ele trabalha em conjunto com o Loop Stream Detector (LSD), introduzido no Bloomfield, que detecta quando o processador está executando um loop de instruções e desliga o circuito de branch prediction, juntamente com as unidades de fetch e decode durante o processamento do loop. O Loop Stream Detector não melhora o desempenho, mas ele permite que o processador economize energia, o que é atualmente um fator tão importante quanto. O cache de instruções leva a economia a um novo nível, permitindo que o processador desligue também as unidades de decodificação de instruções enquanto está utilizando as instruções decodificadas do cache:
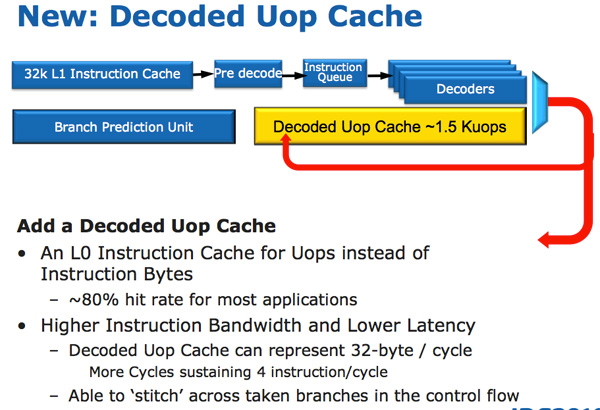
Embora melhore sutilmente o desempenho em diversas situações, a principal função do cache é mesmo a de reduzir o consumo elétrico, o que resulta em um ganho indireto de desempenho, já que permite que o processador passe mais tempo operando nas frequências mais altas do Turbo Boost. Com exceção dele, o cache L1 permanece inalterado, com os mesmos 32 KB para dados e 32 KB para instruções (por núcleo), os mesmos valores usados desde o Pentium III.
Outra mudança foi o aperfeiçoamento do circuito de branch prediction, que adotou um sistema mais eficiente de marcação. Tradicionalmente, são usados dois bits de atributos para cada branch, ou sequência de instruções, sendo que o primeiro bit diz se a sequência foi ou não usada e o segundo indica o nível de certeza (alta ou fraca). Como quase todas as sequências são marcadas com um nível alto de certeza, a Intel optou por compartilhar o mesmo bit entre diversas sequências, permitindo que o circuito monitore quase o dobro do número de sequências.
Essa pequena mudança técnica foi acompanhada por um grande aumento na capacidade do histórico e outras melhorias no circuito, que o tornaram consideravelmente maior (mais transistores) porém mais eficiente, resultando em ganhos em diversas situações. O ganho prático não é muito grande (já que o anterior já era bastante eficiente), mas toda contribuição é válida.
Outra melhoria relacionada com o consumo elétrico do chip foi a adoção do uso do physical register file. A moral da história é que até o Nehalem, bem como até o Phenom II da AMD, cada instrução trafegava dentro do pipeline acompanhada de cada operador usado por ela. Embora seja ideal do ponto de vista do desempenho, este processo é muito dispendioso em termos de energia e número de transistores, já que implica em unidades de execução mais largas e com buffers muito maiores para acomodar o overhead adicional.
No novo sistema, as instruções carregam apenas ponteiros para informações armazenadas em um conjunto de registradores adicionais. Isso permite que os dados continuem disponíveis para quando forem necessários, sem que precisem ser continuamente movidos de um estágio ao outro do pipeline juntamente com as instruções. Isso aumenta bastante a complexidade do projeto (é difícil implementar isso de uma forma que não prejudique o desempenho), mas por outro lado a redução no consumo justifica o esforço. Este mesmo sistema foi adotado pela AMD no Bobcat/Bulldozer, solucionando o mesmo problema.
O uso do registro físico de registradores pavimentou o caminho para a inclusão do AVX, mais uma expansão para as instruções SIMD (SSE), que suporta o uso de operadores de 256 bits e um punhado de novas instruções. O AVX foi adotado também pela AMD, que incluiu o suporte a ele no Bobcat/Bulldozer. Assim como nos conjuntos anteriores de instruções, o AVX depende da disponibilidade de aplicativos otimizados, mas é capaz de oferecer ganhos expressivos de desempenho em algumas áreas.
Diferente do que temos no Clarkdale, onde a GPU é um chip separado e por isso tem seu próprio cache, no Sandy Bridge a GPU compartilha do mesmo cache L3 usado pelos núcleos de processamento. Isso não é necessariamente uma má notícia (já que a concentração dos componentes permite criar uma cache compartilhado maior), mas complicou bastante o design do chip, já que a GPU precisa de quase 2.000 trilhas de dados para a comunicação com o cache (metade para a GPU e a outra metade para a Media Engine), que se somam às mais de 4.000 trilhas usadas pelos quatro núcleos.
Para simplificar o design, a Intel adotou um barramento em forma de anel, que utiliza um único circuito de trilhas (formando 4 anéis independentes) para interligar os quatro núcleos, os quatro blocos de cache L3, a GPU e o System Agent (a ponte norte do chipset, incluída dentro do processador):
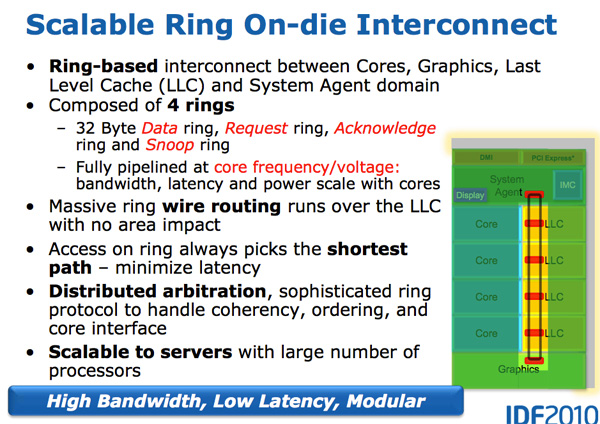
Embora traga algumas vantagens técnicas, o uso de um barramento em anel normalmente aumenta o consumo elétrico e a área utilizada dentro do chip (a ATI adotou um barramento em anel sem sucesso no R600). Não se pode falar com certeza sobre o impacto sobre o consumo elétrico do chip (já que não é possível medir de forma confiável o consumo individual de cada componente), mas a forma como ele foi implementado pela Intel trouxe duas vantagens importantes:
a) Cada anel é capaz de transferir 32 bits por ciclo, o que resulta em 96 GB/s de banda, o que é mesma banda disponível para cada núcleo no Nehalem. Entretanto, como foram implementados 4 anéis independentes, temos na prática uma situação em que cada processador tem disponíveis 96 GB/s quando todos estão usando o cache simultaneamente, mas pode utilizar até 384 GB/s em determinadas circunstâncias, quando o anel está ocioso. O mesmo vale para a GPU, em circunstancias em que os núcleos estão ociosos.
b) A Intel combinou o barramento em anel com um cache L3 de baixa latência, o que resultou em uma latência de apenas 31 ciclos, contra os 36 ciclos no Nehalem. O cache L3 passou a também trabalhar na mesma frequência do processador, eliminando o conceito de “uncore” usado no Nehalem. No Sandy Bridge a frequência da ponte norte do chipset passou a ser chamada de “System Agent” e deixa de ter relação com a frequência do cache.



Deixe seu comentário