64 bytes from gdhs.guiadohardware.net (64.246.6.25): icmp_seq=1 ttl=53 time=8.72 ms
64 bytes from gdhs.guiadohardware.net (64.246.6.25): icmp_seq=2 ttl=53 time=8.62 ms
64 bytes from gdhs.guiadohardware.net (64.246.6.25): icmp_seq=3 ttl=53 time=8.37 ms
— guiadohardware.net ping statistics —
3 packets transmitted, 3 received, 0% packet loss, time 2000ms
rtt min/avg/max/mdev = 8.373/8.576/8.728/0.183 ms
O “-c” indica o número de repetições, neste caso 3. Sem ele, o ping fica enviando pacotes indefinidamente (no Linux), até que você aborte o programa pressionando Ctrl+C. Assim como outros comandos básicos, o ping também está disponível no Windows, através do prompt do MS-DOS.
Normalmente, os pings para qualquer servidor na Internet (com exceção dos servidores do seu provedor de acesso, ou outros servidores muito próximos), voltam com pelo menos 100 milessegundos de atraso. Quanto mais distante geograficamente estiver o servidor, ou quanto mais saturado estiverem os roteadores e links até ele, maior será o tempo de resposta. Um ping muito alto faz com que o carregamento de páginas seja mais demorado (pois o ping determina o tempo necessário para cada requisição do navegador chegar até o servidor) e atrapalha principalmente quem joga online, ou usa programas de administração remota, como o SSH.
No meu caso, consegui pings de apenas 8 ms até o servidor do Guia do Hardware, pois “trapaceei”, acessando via SSH um outro servidor ligado ao mesmo backbone que ele e rodando o ping a partir dele :).
A resposta a pings pode ser desativada na configuração do sistema. No Linux, você pode usar o comando abaixo:
É possível também desativar a resposta a pings na configuração do firewall, de forma que, o fato de um micro da Internet, ou mesmo dentro da sua rede local não responder a pings não significa muita coisa. Se ele responder, significa que está online; se não responder, significa que pode estar online também, porém configurado para não responder aos seus chamados.
Outra função importante do ICMP é o controle do TTL (time to live) de cada pacote TCP ou UDP. Os pacotes tem vida curta e sua única função é carregar os dados até o destino. Eles são transmitidos de um roteador a outro e, uma vez que chegam ao destino, são desmontados e destruídos. Mas, o que acontece em casos onde não existe uma rota possível até o destino, seja porque a máquina está desligada, por erro no endereçamento, ou por um problema em algum dos links?
Existem duas possibilidades. A primeira é um roteador próximo perceber que a máquina está fora do ar e destruir o pacote. Neste caso, ele responde ao emissor com um pacote ICMP “Destination Unreachable”, avisando do ocorrido. Caso isso não aconteça, o pacote fica circulando pela rede, passando de um roteador a outro, sem que consiga chegar ao destino final.
O TTL existe para evitar que estes pacotes fiquem em loop eterno, sendo retransmitidos indefinidamente e assim consumindo banda de forma desnecessária. Graças a ele, os pacotes têm “vida útil”.
O TTL default varia de acordo com o sistema operacional usado. No Windows XP o default são 128 hops, enquanto nas versões atuais do Linux os pacotes são criados com um TTL de 64 hops. Cada vez que o pacote passa por um roteador, o número é reduzido em um. Se o número chegar a zero, o roteador destrói o pacote e avisa o emissor enviando um pacote ICMP “Time Exceeded”.
No Linux, o TTL padrão é configurável através do arquivo “/proc/sys/net/ipv4/ip_default_ttl”. Você pode brincar com isso alterando o valor padrão por um número mais baixo, como em:
Com um valor tão baixo, os pacotes gerados pela sua máquina terão vida curta, e não conseguirão atingir hosts muito distantes. Você vai continuar conseguindo acessar a página do seu provedor, por exemplo, mas não conseguirá acessar servidores geograficamente distantes. Para retornar o valor padrão, use o comando:
Os pacotes ICMP “Time Exceeded” são usados pelo comando “traceroute” (no Linux) para criar um mapa do caminho percorrido pelos pacotes até chegarem a um determinado endereço. Ele começa enviando um pacote com um TTL de apenas 1 hop, o que faz com que ele seja descartado logo pelo primeiro roteador. Ao receber a mensagem de erro, o traceroute envia um segundo pacote, desta vez com TTL de 2 hops, que é descartado no roteador seguinte. Ele continua, enviando vários pacotes, aumentando o TTL em 1 hop a cada tentativa. Isso permite mapear cada roteador por onde o pacote passa até chegar ao destino, como em:
2 poaguswh01.poa.virtua.com.br (200.213.50.90) 9.738 ms 8.206 ms 7.761 ms
3 poagu-ebt-01.poa.virtua.com.br (200.213.50.31) 7.893 ms 7.318 ms 8.033 ms
4 embratel-F3-7-gacc07.rjo.embratel.net.br (200.248.95.253) 8.590 ms 8.315 ms 7.960 ms
5 embratel-G2-3-gacc01.pae.embratel.net.br (200.248.175.1) 7.788 ms 8.602 ms 7.934 ms
6 ebt-G1-0-dist04.pae.embratel.net.br (200.230.221.8) 31.656 ms 31.444 ms 31.783 ms
7 ebt-P12-2-core01.spo.embratel.net.br (200.244.40.162) 32.034 ms 30.805 ms 32.053 ms
8 ebt-P6-0-intl03.spo.embratel.net.br (200.230.0.13) 32.061 ms 32.436 ms 34.022 ms
9 ebt-SO-2-0-1-intl02.mia6.embratel.net.br (200.230.3.10) 298.051 ms 151.195 ms 306.732 ms 10 peer-SO-2-1-0-intl02.mia6.embratel.net.br (200.167.0.22) 269.818 ms peer-SO-1-1-0-intl02.mia6.embratel.net.br (200.167.0.18) 144.997 ms *
11 0.so-1-0-0.XL1.MIA4.ALTER.NET (152.63.7.190) 240.564 ms 147.723 ms 150.322 ms
12 0.so-1-3-0.XL1.ATL5.ALTER.NET (152.63.86.190) 438.603 ms 162.790 ms 172.188 ms
13 POS6-0.BR2.ATL5.ALTER.NET (152.63.82.197) 164.539 ms 337.959 ms 162.612 ms
14 204.255.168.106 (204.255.168.106) 337.589 ms 337.358 ms 164.038 ms
15 dcr2-so-2-0-0.dallas.savvis.net (204.70.192.70) 212.376 ms 366.212 ms 211.948 ms
16 dcr1-so-6-0-0.dallas.savvis.net (204.70.192.49) 396.090 ms bhr2-pos-4-0.fortworthda1.savvis.net (208.172.131.86) 189.068 ms dcr1-so-6-0-0.dallas.savvis.net (204.70.192.49) 186.161 ms
17 216.39.64.26 (216.39.64.26) 185.749 ms 191.218 ms bhr1-pos-12-0.fortworthda1.savvis.net (208.172.131.82) 361.970 ms
18 216.39.81.34 (216.39.81.34) 186.453 ms 216.39.64.3 (216.39.64.3) 245.389 ms 216.39.81.34 (216.39.81.34) 184.444 ms
19 216.39.81.34 (216.39.81.34) 182.473 ms * 182.424 ms
20 * gdhn.com.br (72.232.35.167) 185.689 ms *
Nesse exemplo, o pacote começa passando pelos links da Net (Virtua), passa em seguida por vários roteadores da Embratel, passando por São Paulo e Miami (já nos EUA), para então passar por roteadores da Alter.net e Savvis, até chegar ao destino final.
O Windows inclui o comando “tracert“, que atua de forma similar, porém enviando um ping para cada host. O resultado acaba sendo similar, com exceção de casos em que o servidor é configurado para não responder a pings. Existem ainda vários exemplos de programas gráficos, como o Neotrace (para Windows), que você encontra em qualquer site de downloads e o Xtraceroute (para Linux).
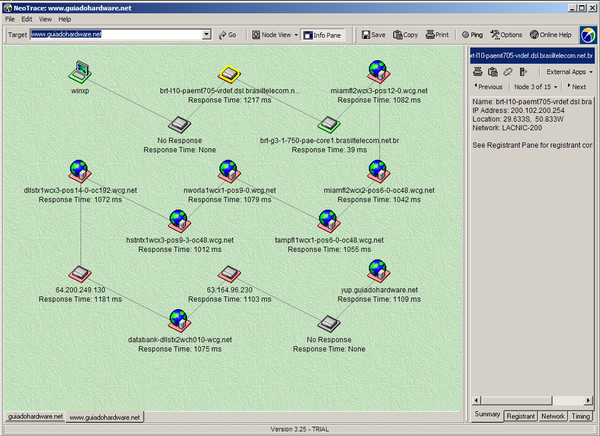
Eles exibem as mesmas informações, porém de uma forma bem mais agradável. Este é um exemplo do Neotrace mostrando uma conexão especialmente ruim com um servidor hospedado no exterior, a partir de um link ADSL da Brasil Telecom. Veja que o problema começa em um roteador congestionado, da própria operadora (com tempo de resposta de mais de 1200 ms!) e continua em uma seqüência de links lentos da wcg.net:

Na Internet, os roteadores são espertos o suficiente para conhecerem os roteadores vizinhos e escolherem a melhor rota para cada destino. Sempre que um roteador fica congestionado, os demais passam a evitá-lo, escolhendo rotas alternativas. Essa comunicação é feita através de pacotes ICMP “Redirect”, que avisam o emissor que uma rota mais rápida está disponível e os pacotes seguintes devem ser encaminhados através dela.
Naturalmente, este sistema não é infalível. Corrupções nas tabelas de roteamento, bugs nos softwares de controle, panes e defeitos em geral podem comprometer o trabalho dos roteadores, fazendo com que alguns pontos da rede fiquem inacessíveis. Surge então o clássico problema de um determinado endereço ou faixa de endereços ficar inacessível para usuários de um determinado provedor, muito embora continue disponível para o resto da rede.
Em vez de procurar algum amigo no MSN e perguntar “está funcionando daí?”, você pode lançar um traceroute a partir de um servidor localizado em outro ponto da rede e assim checar se o endereço realmente está indisponível, ou se o problema é relacionado à sua conexão.
Existem diversos servidores na web que oferecem este serviço como cortesia. Estes “servidores de traceroute” são chamados de “looking glasses” e são bastante numerosos. Alguns exemplos são:
https://registro.br/cgi-bin/nicbr/trt (aqui no Brasil)
https://easynews.com/trace/ (EUA)
https://216.234.161.11/cgi-bin/nph-trace (Canadá)
https://cadiweb.idkom.de//lookingglass.php (Alemanha)
https://www.bilink.net/cgi-bin/trace.cgi (Itália)
https://www.kawaijibika.gr.jp/trace.shtml (Japão)
Através deles você pode checar a conectividade do endereço com hosts em diversas partes do mundo e o tempo de resposta para cada um. Você encontra uma lista com vários outros servidores públicos no https://traceroute.org/.
Diagnosticar o problema de conectividade permite indicar o culpado, mas não resolve nosso problema imediato. O que fazer se você precisa acessar o servidor do seu site para fazer uma atualização importante e ele está inacessível a partir da sua conexão atual?
A solução é usar uma terceira máquina, que tenha conectividade com as duas, para intermediar a conexão. Se você administra dois servidores diferentes, por exemplo, poderia usar o segundo servidor para conseguir se conectar ao primeiro. Você poderia também usar a máquina de algum amigo (que acesse através de outra operadora) que confie em você e lhe dê um login de acesso. Você pode então se logar na máquina dele (via SSH, VNC ou outro protocolo de acesso remoto) e fazer o acesso a partir dela.
É possível também usar o SSH para criar um túnel, fazendo com que os pacotes destinados a uma determinada porta do servidor inacessível sejam encaminhados até ele através do segundo servidor. O comando é um pouco complicado, mas é um exercício interessante.
Imagine que quero acessar o servidor “gdhn.com.br”, que está inacessível a partir da minha conexão atual, usando o servidor guiadohardware.net como intermediário. Estou logado na minha máquina local como “morimoto”, que é o mesmo login que uso no “gdhn.com.br” e uso a conta “gdh” no servidor “guiadohardware.net. Poderia então usar o seguinte comando:
Isso criaria um túnel entre a porta 2222 da minha máquina e a porta 22 do servidor gdhn.com.br, com o servidor guiadohardware.net servindo como intermediário. Com o túnel criado, posso acessar o gdhn.com.br via SSH usando a porta 2222 da minha própria máquina, veja só:
Naturalmente, para fazer isso é necessário ter contas de acesso nos dois servidores e fazer com que ambos tenham o servidor SSH instalado, mas é uma dica que pode lhe salvar na hora do aperto.
Concluindo, os pacotes ICMP são usados (durante as transferências de dados) também para regular a velocidade da transmissão, fazendo com que o servidor envie pacotes na maior velocidade possível permitida pelo link, sem entretanto sobrecarregar o link do cliente. Sempre que um dos roteadores pelo caminho, percebe que o link está saturado, envia um pacote ICMP “Source Quench”, que faz o servidor reduzir a velocidade da transmissão. Sem isso, os pacotes excedentes seriam descartados, causando um grande desperdício de banda.